
Stack Building
[스크랩] 서포트 벡터 머신 본문
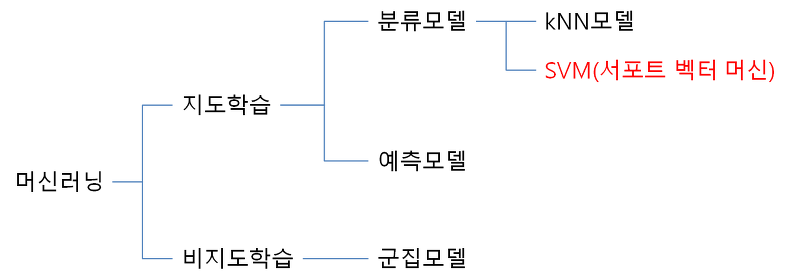
분류모델: 어떤 정해진 값 중에서 하나의 결과를 도출해내는 것
여러 선택지 중 하나의 결과를 도출하는 것
kNN 모델의 원하는 결과는 방대한 데이터가 어떤 분류에 속해있는가를 나타내며,
SVM 역시 이와 마찬가지로 어떤 분류에 속해있는가를 선별하는 알고리즘입니다.
즉 알고리즘의 방식이나 접근 형태가 다른 것이지,
궁극적으로 목표하고자 하는 바는 동일하다고 보시면 됩니다.
(1) 퍼셉트론(Perceptron)의 정의 및 구성
서포트 벡터 머신을 다루는데 왠 시작부터 퍼셉트론인가 의문이 갈 수 있을 것입니다.
그 이유는, 서포트 벡터 머신(SVM)의 구현이
퍼셉트론의 개념을 가져와서 분류를 하는 방식이기 때문입니다.
그렇기 때문에 SVM을 이해하기 위해서는 먼저 퍼셉트론에 대한 이해가 선행되어야 합니다.
퍼셉트론은 인공신경망을 구성하기 위한 기본적인 토대이며,
기본 역할은 입력 신호를 받고 함수를 통해 출력값을 나타내는것입니다.

여기까지만 보면, 전산학 또는 수학 전공자한테는 이게 무슨 이론이냐 당연한 이치 아니냐고 생각할 수가 있겠죠. 하지만 프로그래밍 또는 수학적 함수의 개념과 원리는 똑같지만 약간은 다르게 접근해야 할 것입니다.
퍼셉트론은 인공신경망의 토대입니다.
인공신경망의 기본 원리는 신경이 어떤 입력이 들어올때 어떻게 반응하는지를 구성하는 것입니다. 그러나 그 신경망은 단순히 하나의 입출력값이 고정된 것이 아니라, 수많은 학습과 반복에 의해서 특정 결과가 도출되는 것이죠. 즉 퍼셉트론은 입출력 간에 어떤 식으로 학습이 되어 어떤 함수를 만드는가를 나타내는 이론으로 보시면 됩니다.
그렇기 때문에, 퍼셉트론의 함수는 어떠한 고정된 형태가 아닌, 학습된 형태의 함수를 뜻하는 것입니다. 한마디로 퍼셉트론의 함수는 학습된 정도에 맞게 필요에 따라 변형될 수 있습니다.
그럼 퍼셉트론이 어떤 식으로 구성되는지를 설명해 보겠습니다. 퍼셉트론의 입력은 숫자값 1개에 국한되지는 않습니다. 벡터값 역시 퍼셉트론의 입력값이 됩니다. 그러므로 퍼셉트론의 구성은 벡터를 기준으로 간단히 설명하겠습니다.
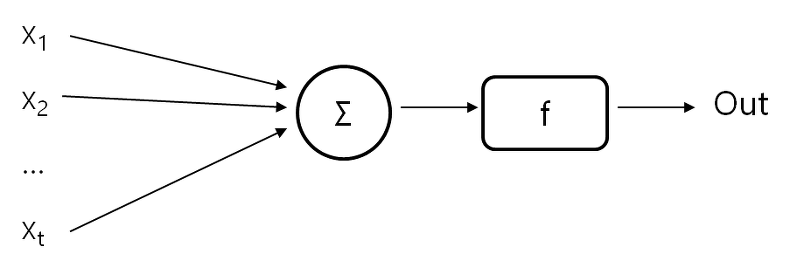
(제가 그린 그림이므로 출처기재는 생략, 퍼셉트론 관련 예제에 많이 나오는 그림이므로 저작권표시 역시 생략)
벡터 x가 있고, x의 구성요소인 x1, x2, ..., xt 등이 있습니다.
이를 계산하는 함수는 상기 그림과 같이 Σ(Sum)으로 되어 있으며,
각 구성요소에 별로 가중치(w1, w2, ..., wt)를 가지고 있습니다.
그러므로 여기에서의 기본 함수 형태는 다음과 같이 나타납니다.
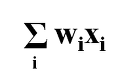
그리고 그 다음에 f라는 함수가 또 있습니다. 여기에서 이 함수는 활성화 함수(activation function)이라고 하며, 활성화 함수의 결과값은 1,0으로 구성되어 있습니다. 즉 TRUE와 FALSE의 이진값으로 보셔야 되겠지요.
퍼셉트론이 인공신경망의 토대인 만큼, 인공신경망의 뉴런은 단일입력에 의한 단일출력이 아니겠지요. 하나가 입력되고 여러곳으로 출력되기도 하고, 그 출력값을 또 다른 뉴런의 입력으로 전달이 되고.. 그래서 활성화 함수의 전달방식은 값이 TRUE일 경우 다음 뉴런으로 전달되고, FALSE일 경우 전달되지 않습니다.
그렇다면 활성화함수는 어떤 식으로 되어 있을까요.
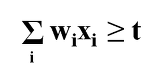
상기 언급한 퍼셉트론 공식의 값과 t라는 임계값을 비교하게 됩니다. 위 공식이 TRUE일 경우 활성화 함수의 값은 1이고, FALSE일 경우 활성화 함수의 값은 0이 되는 방식입니다.
퍼셉트론의 기본개념은 여기까지입니다.
단일 퍼셉트론, 다중 퍼셉트론 등등 세부적으로 파고들면 다룰 내용이 계속 나오지만, 지금은 인공신경망 및 퍼셉트론쪽보다는 서포트벡터머신(SVM)을 다루는 글인 관계로 퍼셉트론의 기본 개념만 언급한 것이니 참고 바랍니다.
그럼 이제 가장 중요한 부분까지 언급하고 SVM으로 들어가곘습니다.
퍼셉트론은 위와 같이 벡터 입력값, 가중치 및 연산함수, 활성화함수 및 이를 위한 임계값으로 구성되어 있습니다. 퍼셉트론의 함수는 고정된 형태가 아닌, 학습된 형태의 함수라고도 언급하였고요. 여기서 학습되었다라는 것은 무엇을 뜻할까요. 입력값이 들어왔을 때 원하는 결과를 도출해 내기 위해서는 가중치 및 임계값 설정이 잘 되어 있어야 합니다.
이를 초기에 설정한 후 다음 데이터를 입력했을 때 원하는 결과가 나온다면 문제가 없지만, 오차범위가 크게 발생한다면 가중치 및 임계값이 유효하지 않기 때문입니다. 그래서 이 때 가중치, 임계값을 변경하는 과정을 학습되었다라고 하며, 함수 역시 그에 맞게 변경이 됩니다. 퍼셉트론의 입력값이 계속 늘어나고, 이에 따른 오차범위가 줄어들고 충분히 학습된 함수가 있다면 결국 이 함수에 대한 신뢰도는 높아질 수밖에 없을 것입니다.
SVM에서 다룰 퍼셉트론 역시 들어오는 입력값을 토대로 가중치, 임계값 등을 조정하면서 원하는 함수를 만들 것이고, 이를 기반으로 수많은 데이터를 분류하는 방식으로 이해하시면 되겠습니다.
(2) SVM의 정의 및 활용
SVM은 앞서 다뤘던 kNN과 마찬가지로 지도학습의 분류모델 중 하나로, kNN과 마찬가지로 훈련데이터/테스트데이터가 있어야 합니다. SVM의 분류 방식은 크게 선형 분류와 비선형 분류가 있으며, 실습 예제는 선형 분류를 위주로 다룰 예정입니다.
비선형 분류의 경우 커널 트릭(Kernel Trick), 방사 기저 함수(RBF), 하이퍼볼릭 탄젠트(Hyperbolic tangent), 가우시안 방사 기저(Gaussian radial basis)함수, 다항함수(Polynomial function) 등등을 사용해야 하지만, SVM의 개념을 이해하고 기초적인 실습 및 학습을 하기에는 난이도가 있기 때문이지요.
앞서 언급한 바와 같이, SVM은 퍼셉트론의 개념을 토대로 하여 데이터를 분류하는 방식입니다. 즉, kNN은 훈련데이터를 기반으로 나눠진 분류에 인접을 판단하여 테스트데이터를 분류하는 방식이면, SVM은 훈련 데이터로 퍼셉트론 함수를 사전에 정의한 후, 테스트 데이터를 토대로 분류를 하면서 학습을 하는 형태입니다. 말 그대로 퍼셉트론 함수를 기반으로 분류하는 모델이므로, 해당 함수의 형태에 따라 선형 분류 및 비선형 분류로 나눠지게 됩니다. SVM은 이미지 인식, 패턴 인식에 활용된다 하였으며, 텍스트 분류 또한 가능하다고 책에 명시가 되어있으며, 인공신경망과도 유사하다는 점에서 의료 분야에서도 SVM을 많이 사용한다고 합니다.
(3) 선형 분류
선형분류는 아래의 그림을 보면서 설명하겠습니다.
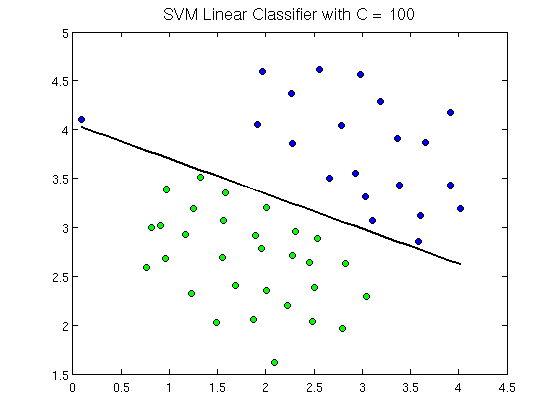
출처: 스탠포드(Stanford)대학교 강의자료
위에 보시다 시피, 각 데이터가 그림 상에 분포가 되어 있습니다. 여기에서 분류할 객체는 점(point)라 부르고, 모든 점에는 여러 특성(set of features)을 가지고 있습니다.
눈으로 보면, 파란 점은 위에 있고 녹색 점은 아래에 있고 그 가운데에 선이 있습니다. 그러나 이 선은 단순히 생긴 선은 아니고, 수학적으로 계산이 되어서 이루어진 선입니다. 이 선을 분리선이라 부르고 초평면(hyperplane)이라 부르기도 합니다. 분리선은 하나의 함수로 분류되어 있으며, 함수의 결과값은 1과 -1로 나타납니다. 이 때 개체가 어떤 분류인지는 결과값으로 표현할 수가 있습니다. 예를 들어서 파란색 점을 나타내는 개체는 분리선의 결과값이 1인 경우가 될 수 있겠고, 녹색 점의 개체는 결과값이 -1인 경우로 보시면 됩니다.
그렇다면 이를 토대로 SVM에서 선형 분류가 어떤 방식으로 이루어지는 지를 살펴보겠습니다.

출처: Wikipedia
위 그림은 첫번째 그림과 유사한 면이 있지만, 초평면이 좌측 상단 점선에서 우측 하단 점선까지의 면으로 구성되어 있습니다. 실제 SVM에서 사용되는 초평면도 위 그림을 사용하고 있기 때문에, 위 그림에서의 초평면 개념을 먼저 알아두도록 합니다. 가운데 실선은 주 초평면 선(main hyperplane line)으로, 초평면의 가장 중심이 되는 선이며, 이에 대한 공식은 다음과 같습니다.
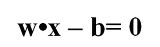
x는 개체를 나타내며, w는 개체 x에 대한 가중치를 나타냅니다. 그리고 w와 x 사이의 점은 어떠한 하나의 연산이 되며, b는 bias값으로 절편을 뜻하며, 위 그림에서는 y축과 만나는 지점이 됩니다.
다음은 초평면의 양쪽 바깥쪽에 있는 점선입니다. 이들 점선은 에지 초평면(edge hyperplane)이라 하며, 각각 다음과 같이 나타납니다.

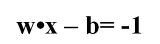
위 그림을 다시 보면, +1을 나타내는 초평면에 걸친 개체가 있고, -1을 나타내는 초평면에 걸친 개체가 있습니다. 이들 개체를 서포트 벡터(Support Vector)라 합니다. 즉 서포트 벡터 머신은 분리선(초평면)을 기준으로 하였을 때 +1에 걸친 개체와 -1에 걸친 개체를 찾아내고, 이를 바탕으로 분류를 형성하는 원리로 구성됩니다.
여기에서 테스트 데이터가 새롭게 들어오게 되면 어떻게 될까요. 만약 테스트 데이터가 SVM의 에지 초평면 바깥쪽에 있을 경우 +1이나 -1 값을 나타내면서 특정 분류로 들어갈 것이고, 그렇지 않을 경우에는 분류 함수 역시 이에 맞게 변형되어야 합니다.
SVM이 퍼셉트론의 개념을 따른다는 점에서 SVM의 초평면 함수는 퍼셉트론과 동일하다 볼 수 있습니다. 퍼셉트론이 원하는 결과의 도출을 위해서 가중치와 임계값을 설정하면서 학습된 함수로 변형되듯이 SVM의 초평면 함수 역시 가중치(w)와 바이어스 값(b)을 변형시키면서 원하는 분류를 형성할 수 있습니다.
양쪽 에지 초평면의 마진(margin)은 당연히 클수록 좋습니다. 에지 사이의 간격이 클수록 분류의 신뢰도가 그만큼 높아지기 때문입니다.
여기까지가 SVM에서의 선형 분류 방법입니다. 사실 수학공식도 다수 들어가 있고 저도 처음 이해하는 개념이다보니 여러가지로 어려운 것은 사실이지만, 분류 모델의 하나라는 점에서 어떤 방법으로 분류하는가를 이해하는 것에 초점을 두어서 설명했습니다. 실제 SVM을 프로그래밍하게 된다면, SVM 라이브러리를 사용하여 w와 b값을 도출해내면서 분류하는 방식이 되겠지요?
출처: https://onikaze.tistory.com/375 [관념과 사고] 본문 일부 수정
'머신러닝' 카테고리의 다른 글
| Bagging, Boosting, Stacking (0) | 2019.09.02 |
|---|---|
| [스크랩] 잔차(residual)와 오차(error) (0) | 2019.08.15 |
| [스크랩] 유클리드, 마할라노비스 거리 (0) | 2019.08.04 |
| [스크랩] 확률과 가능도(우도) (0) | 2019.08.04 |
| 클러스터링 (k-means 알고리즘) (0) | 2019.06.11 |



