
Stack Building
[python] Selenium을 이용한 Web-Scraping 본문
환경 설정
1. 파이썬과 필요한 라이브러리 requests beautifulsoup4 selenium
2. 크롬 드라이버 73버전 (https://sites.google.com/a/chromium.org/chromedriver/downloads)
목표
- 아고다(www.agoda.com)에서 특정 날짜, 특정 지역 숙소를 저렴한 비용 순으로 스크래핑
1. beautiful soup으로 스크래핑하기
1.1 검색창 접근하기

아고다 홈페이지 화면 중앙의 검색창을 소스코드에서 접근한다.
정상적으로 실행될 경우 인풋 태그가 출력되지만,
여기서는 출력되지 않는다.

를 해 보면, 인풋 태그는 아예 찾을 수 없을 것이다.
아고다가 리액트를 이용해 개발한 사이트이기 때문이다.
단순하게 request의 response에 들어있는 content를 받았다면,
자바스크립트가 실행되기 이전의 html을 가지고 있다.
참고: lazy-loading (실제로는 텍스트 박스가 없는 상태의 html이 넘어옴)
2. selenium으로 스크래핑하기
2.1. 검색창 접근하기

이 라이브러리를 쓰는 이유는 로딩을 셀레니움으로 시켜줄 수 있어서다.
즉 직접 웹 브라우저로 들어가서 로딩이 된 화면을 보고자 함이다.
셀레니움은 우리가 코딩한대로 자동화된 웹브라우저를 보여준다.
뷰티풀숩으로 잘 안 되는 경우, 웹사이트를 개발했을 때 테스트하는 매크로를 만들 경우 등에 쓰인다.
윈도우에서는 파일 확장자까지 모두 명시해야 제대로 드라이버로 들어온다.
웹드라이버로 아고다에 접속한 후에는 1. 같은 실수가 일어나지 않도록 자바스크립트가 로딩될 시간을 줘야 한다.
driver.implicitly_wait(3)을 쓰면 드라이버가 자체적으로 3초간 기다리고,
이 함수가 듣지 않을 경우 sleep 메소드로 파이썬 프로그램 자체의 실행을 몇 초 지연시킨다.
웹드라이버의 페이지 내용을 뷰티풀숩으로 가져와 1. 과 같은 방법으로 처리한다.

이 부분의 검색창 부분이 불려와서
[<input aria-label="도시, 지역, 숙소명, 관광 명소 등으로 검색" class="SearchBoxTextEditor SearchBoxTextEditor--autocomplete" data-selenium="textInput" placeholder="도시, 지역, 숙소명, 관광 명소 등으로 검색" tabindex="-1" type="text" value=""/>]
위와 같은 결과가 나오게 된다.
2.2 필요한 url을 가져온다.
일단 우리가 원하는 데이터를 검색해둔 url이 필요하다. 예를 들어 제주도가 원하는 곳이라고 가정하면, 일단 아고다에 제주도를 검색하고 결과 url을 가져와야 한다. url은 아주 길지만, 필요한 파라미터는 얼마 되지 않는다.
추려내보면 아래와 같다.
checkIn=
checkOut=
rooms=
adults=
children=
priceCur= (*통화. 한국 돈으로 지불한다면 KR 입력.)
textToSearch= (*검색어)
여기서 textToSearch에 한국어를 입력할 경우 이상한 모양의 문자열이 나온다. 제주도의 경우 %EC%A0%9C%EC%A3%BC%EB%8F%84%EB%8F%84라고 나오는데, 이것은 url encoding 혹은 percent encoding 이라고 불리는 인코딩 방식이다. 한글 검색어를 대신 넣어도 정상적으로 동작한다.
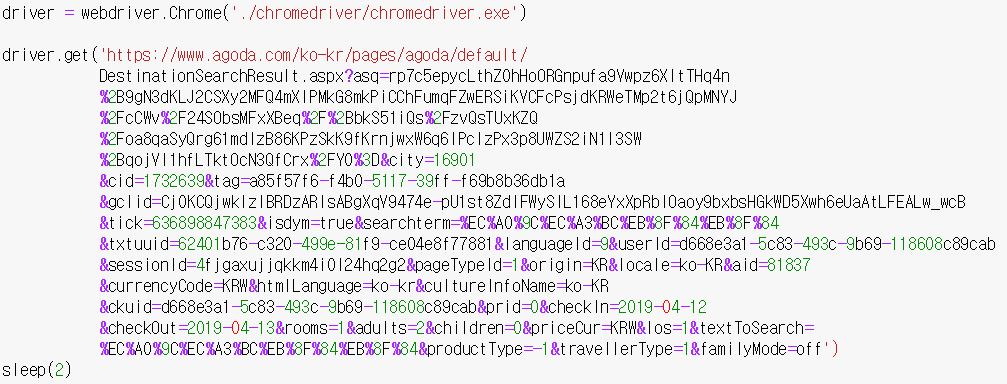
파라미터를 수정한 url을 드라이버가 받아오게 한다. 돌려봤을 때 새로운 결과창으로 원하는 결과가 뜬 화면이 나왔다면 정상적으로 동작하고 있는 것이다. 예제를 위해 캡처한 것이기 때문에 일부러 줄바꿈을 한 것이지 실제로는 그냥 한 라인에 다 넣어야 한다. 이 url을 통해 아고다로 들어가면 날짜를 선택하는 창이 나오게 된다.
2.3 날짜 선택은 나중에 하고 낮은 요금 순서대로 보게 하기

날짜 선택하는 창을 닫게 하기 위해 나중에 하기를 클릭하는 코드를 작성한다.
태그를 찾아서 클릭하게 해주는 코드이다.
그리고 잠시 기다렸다가 (여기서는 1만 했지만, 3 정도를 하는 것이 좋다.)

드라이버에게 '낮은 요금 먼저'를 클릭하게 한다.
웹 드라이버의 검색 결과가 '낮은 요금 먼저'로 정렬되어 있는 것을 확인할 수 있다.
2.4 더 이상의 로딩이 없을 때까지 스크롤 내리기

아고다는 동적인 웹사이트기 때문에 스크롤을 내릴 때마다 조금씩 데이터를 로딩한다. 스크롤 내린 이후로 로딩된 데이터로 스크롤 정보가 변경되므로 더이상의 로딩이 없을 때까지 스크롤을 내려야 한다. 웹브라우저는 스페이스 키로 스크롤을 내리는 것을 지원한다. 따라서 action chains를 사용하여 셀레니움에게 스페이스 키를 누르면서 로딩하도록 만들고, 키보드 인풋을 받기 위해 keys를 사용한다.
실제로 해보면, 아고다에서는 1초 간격으로 15번 정도 스페이스 바를 누르면 스크롤바가 길어진다. 여유롭게 20회 가량 눌러보고 스크롤 변화를 확인하는 것이 좋다. 이 함수는 스페이스 키를 누르고 스크롤 변화까지 비교해준다. 만약 이 과정이 끝나면 loading complete가 뜬다.
2.5 로딩된 데이터 수집하기

여기서는 뷰티풀숩을 다시 사용한다.
먼저 각 호텔별 이름과 가격을 저장하기 위한 클래스를 만든다.
아래는 각 아이템별 정보를 추출하기 위한 코드다. 빈 hotels 리스트를 만들고 이름 정보와 가격 정보를 호텔 객체로 만들어 리스트에 넣는다.
그리고 리스트를 출력해보면 호텔이름+가격 의 형태로 리스트가 출력되는 것을 볼 수 있다.
주의
1. 에러가 자꾸 날 경우 시간을 (ex. sleep) 조정한다. 앞의 활동이 안 끝났는데 뒤에서 시작하면 에러가 난다.
2. local에 깔린 라이브러리가 주피터 노트북에서 없다고 뜰 경우 conda를 쓰고 있다면, conda install을 한다.
3. 절대 이 과정 중에 드라이버가 켠 브라우저를 마음대로 닫지 않는다.
4. 윈도우 64비트에 해당하는 크롬드라이버가 없더라도 당황하지 말자. 32비트가 64비트도 지원한다.
참고
'머신러닝' 카테고리의 다른 글
| 기계학습 (0) | 2019.04.16 |
|---|---|
| [python] 시작하기 (0) | 2019.04.16 |
| 인공지능의 한계 (0) | 2019.04.16 |
| 내적 (0) | 2019.04.03 |
| terminology (0) | 2019.03.18 |

