
Stack Building
기계학습 본문
1. 기계 학습


- 인간이 가지고 있는 학습 능력을 로봇이나 컴퓨터에서 실현하는 기술
- 인공지능 분야에서 수학적인 기초가 잘 잡혀있는 분야
2. 지도학습(Supervised Learning)
- '지도': 학습에 사용되는 자료의 정답
- 정답이 있는 학습 데이터(Training Data)를 통해 학습을 수행하여 예측(또는 인지) 모형을 구성
따라서 정확한 답이 존재하는 양질의 데이터가 주어지는 것이 중요.
- 학습된 모형을 정답이 있는 검증 데이터를 통해 성능을 향상시킴
ex. 강아지 사진 10장 학습, 고양이 사진 10장 학습 후 강아지/고양이 맞추기
ex. 면적, 화장실 갯수, 시세를 학습, 시세 예측
- 지도학습 수행의 필수요소

- 학습 데이터(Training Data) : 모델 학습에 필요한 자료
- 검증 데이터(Test Data) : 학습 결과를 검증하기 위한 자료
2.1 패턴 인식(Pattern Recognition)
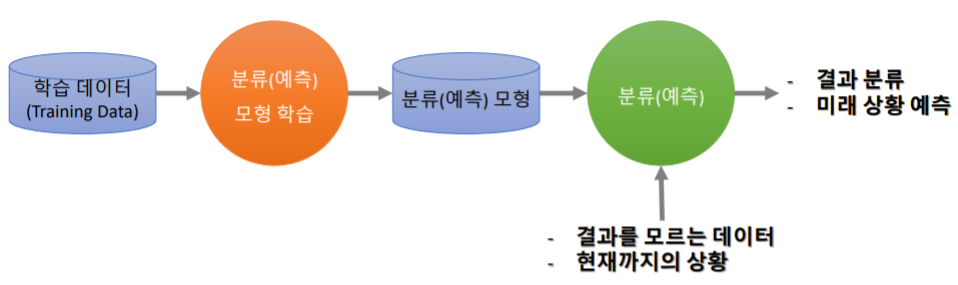
- 학습데이터로부터 결과를 분류(또는 예측)하는 모형을 학습한후 새로이 관측된 데이터의 결과를 판단
- 예시: 문자 인식

2.1.1 패턴인식의 접근법: 선형 회귀(Linear Regression)
- 실수로 표현된 입력 데이터에 대해 실수 값을 출력하는 선형 함수 관계를 학습
- 학습 후 미지의 입력 데이터의 출력 값을 예측
- 데이터를 설명하는 특징들과의 관계를 잘 조합해야 함
- 일상 생활의 많은 현상은 선형적 성격을 가지는데, 이러한 관계에 적용하는 대표적인 기계학습 이론
- 회귀로 패턴 인식하는 방식: 선형회귀, 일반선형회귀모형, 커널회귀, 가우시안프로세스회귀
- 예시: 키와 몸무게의 관계

예시2. 하루 노동 시간과 월급의 관계

-성실히 일하면 돈을 많이 벌 수 있을 것이다?
하루 일하는 시간 월급
* 학습
- 주어진 데이터를 표현하는 가장 합리적인 직선을 찾아내는 것
인간은 개념을 정리하기 위해 가설을 세우고, 검증하고, 반복적으로 수정하고, 최종적으로 하나의 개념을 정리한다.
선형 회귀 학습도 같은 방법으로, 합리적인 직선을 스스로 찾아내도록 진행한다.
 |
 |
- 데이터가 최소 3개 이상이어야 의미가 있음
- 처음에는 k-means에서 랜덤으로 중심점을 찍는 것처럼 직선도 일단 랜덤으로 긋고 시작한다.
* 가설을 검증하는 방법
- 비용: 목표 지점에 도착할 때 까지 소모되는 자원 (ex. 돈, 시간, 에너지 등)
- 기계학습에서 비용: 가설이 얼마나 정확한지 판단하는 기준 (비용이 적을수록 좋은 가설)
 |
 |
- H = wx + b 라고 가정한 식을 표현하자. H는 가설, w는 직선의 기울기(가중치), b는 y 절편(편향)이다.
- x는 input이기 때문에, 합리적 직선을 찾는다는 것은 합리적인 w와 b를 찾았다는 것을 의미한다.
- 오른쪽 그림에서 제곱을 해주는 이유는 양수로 값을 바꾸기 위해서기도 하고, 소위 '뻥튀기'를 하면 가까운 것은 더 가깝게, 먼 것은 더 멀게 해주기 때문이다.
* 가설을 수정하는 과정
- 경사 하강: 기울기를 조금씩 변경하여 최소의 비용을 탐색하는 방법
- “계산된 비용은 학습을 반복하면서 점점 감소한다”
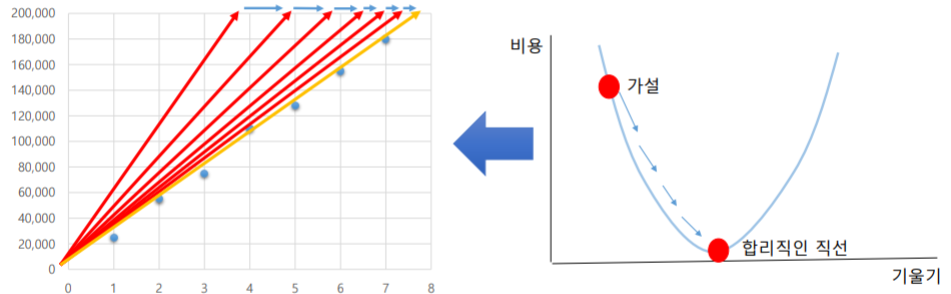
미분을 이용해서 곡선의 접선 기울기를 구하면 곡선의 골짜기가 어디 있는지 알 수 있다.

- 주의: 하강폭은 사람이 결정하는 것으로, 너무 적게 하강하면 학습 시간이 오래 걸리고, 너무 많이 하강하면 학습 결과가 부정확해지는 것에 유의해야 한다.
2.1.2 패턴인식의 접근법: 분류(Classification)
- 학습데이터에 포함된 정답들을 바탕으로 데이터와 정답의 관계를 분류
- 실수형 데이터, 범주형 데이터 전부 사용 가능.
- 정답이 부여된 데이터 집합을 학습 데이터로 사용
- 학습 후 미지의 입력 데이터가 어떤 답을 갖는지 예측
- 회귀에 비해 정확도는 다소 떨어지는 편.
- 분류로 패턴 인식하는 방식: 의사결정나무, 퍼셉트론, 신경망, SVM, 랜덤포레스트, 나이브베이즈혼합필터
- 예시: 날씨에 따른 테니스 출장 여부 예측하기


2.1.2.1 의사결정나무 (Decision Tree)
(1) 개념

- 학습 데이터를 분석하여 이들 사이에 존재하는 패턴을 속성(특징)의 조합으로 나타내는 분류 모형
비지도학습에서는 이걸 사람이 주는 경우가 많은데, 지도에서는 정답을 정답으로 만드는 특징을 기계가 스스로 판단하게끔 함.
- 데이터로부터 나무(tree) 구조의 일반화된 지식을 추출
- 예측 과정에서 설명이 필요한 경우 유용하게 사용
(2) 나무 구축 과정
ㄱ. 의사결정나무 형성: 학습 목적과 자료에 따라서 적절한 분리기준(split criterion)과 정지규칙(stopping rule)을 지정하여 의사결정나무를 얻음
분리기준: 하나의 뿌리 안에 데이터를 잘 분리해줄 특징을 찾는다.
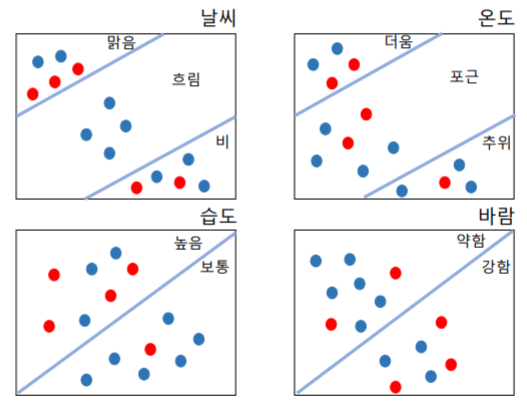
이 경우에는 "날씨"가 분리기준으로 가장 좋다. "순수도"가 높을수록 좋은 분류이다.
의사결정나무는 자식 노드의 순수도가 증가하도록 나무의 부모 노드를 분류해 나간다.
순수도란 노드에 포함된 데이터가 모두 동일한 집단 또는 해답에 속하는 것을 말한다.
이처럼 좋은 분리를 하려면 분리기준을 사용하는데,
이산형 목표변수일 경우 카이제곱 통계량의 p값, 지니지수, 그리고 엔트로피를 사용한다.
엔트로피란 열역학 개념으로, 무질서도에 대한 측도이다. 쉽게 말하면, 혼잡도 또는 섞인 정도다.
엔트로피 지수가 작은 특징을 선택하여 이를 기준으로 자식 노드를 형성한다.
* 엔트로피 계산하기 *
로그(어떤 수를 나타내기 위해 고정된 밑을 몇 번 곱하여야 하는지를 나타내는 함수) 사용
 |
 |
특징별로 계산한 전체 엔트로피는 날씨 0.69, 온도 0.91, 습도 0.79, 바람 0.89로
날씨가 가장 뿌리 노드의 분류를 잘하는 특징이 된다.

입사기에는 더이상 분류할 필요 없는 것(ex.흐림)이 있는 조건으로 설정하고,
나눠져 있는 데이터 뭉치로 또 엔트로피를 계산해서 분류기를 설정한다.
ㄴ. 가지치기(Pruning)
- 구축된 모형에 테스트 데이터 적용하여 예측 정확도를 측정
- 오분류율을 크게 할 위험이 높거나 부적절한 규칙을 가지고 있는 가지를 제거
ㄷ. 타당성 평가: 검증용 데이터(test data)에 의한 타당성 평가를 통해 의사결정나무 평가
ㄹ. 예측: 의사 결정 나무로 예측 모형 설정
2.1.3 패턴 인식 과정

3. 비지도학습(Unsupervised Learning)
- 정답이 없는 데이터를 통해 학습을 수행
- 학습 결과의 향상은 오직 학습기에 탑재된 규칙이나 절차에 의해 수행
ex. 캐릭터 100개에 대해 유사성에 기초하여 그룹으로 분류
ex. 특징이 비슷한 사람끼리 같은 위치에 있도록 배치
3.1 클러스터링

- 데이터(또는 객체)의 모임을 데이터의 유사도에 따라 몇 개의 그룹으로 분류하는 것
- 분류를 위한 사전 지식은 제공되지 않음 = 비지도 학습
- 클러스터링은 데이터를 자동으로 분류할 뿐, 각각의 클러스터에 ‘삼각형, 원, 사각형’ 같은 개념을 자동으로 형성 X
- 인간이 스스로 개념을 형성하기 위해 본능적으로 비슷한 특징을 갖는 데이터(객체)를 하나로 모으듯이, 클러스터링은 스스로 개념을 획득하는 인공지능을 만드는데 매우 중요한 요소
- 클러스터링 과정:

3.1.1 특징 선택
- 특징 선택 가장 중요 (데이터 "성격"을 명확히 나타낼 수 있도록 하는 것 중요)
- 클러스터링을 수행하기 위해 객체간의 비슷한 정도를 유사성으로 반영
- 객체와 객체의 유사성을 계산하기 위해 각 객체의 특징 값을 정의
- 어떤 분류가 자연스러운지는 어떤 특징에 따라 클러스터링 했는지에 좌우된다

- 3만개의 특징 = 100*100(사이즈)*3(RGB)
- 벡터 = 특징값의 집합.
- 특징을 구성하는 특징 벡터가 크다고 클러스터링의 정확도가 높아지지는 않음
- 객체의 특징을 잘 포착하면서 크기가 작은 특징 벡터를 구성하는 것이 매우 중요 (성격 잘 나타내는 특징으로만 구성)
3.1.2 특징값 표현 방식
수치형 값 – 값이 수치로 표현(예: 신장, 체중, 혈압)
범주형 값 – 값이 몇 개의 범주로 표현(예: 성별(남/여), 혈액형(A/B/O/AB))
특징값이 수치형인지 범주형인지에 따라서 유사도를 구하는 방식이 서로 달라짐.
범주형을 수치형으로 바꿀 경우 일반적으로 다른 값에도 영향 미치므로 하지 말 것.
3.1.3 유사도 계산
- 클러스터링은 보통 각 특징 값의 일치 확률이나 벡터 공간에서의 거리를 유사도로 적용
- 수치형 값: 벡터 공간에 표현된 객체의 특징 값간의 거리 ex. 피타고라스 정리
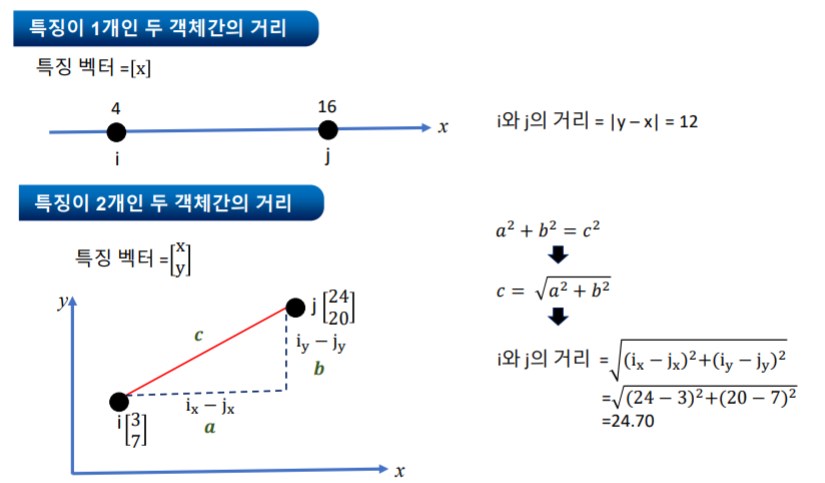

- 범주형 값: 객체의 각 특징 값이 일치하는 정도를 적용 (일치한 특징 값의 개수 / 전체 특징 값의 개수)
또는 객체의 각 특징 값을 벡터 공간에 사상(Mapping)하여 거리를 측정 (그래프)

3.2 K-means 클러스터링
- 평균을 적용하여 같은 클러스터의 내부 유사도를 증가시키는 방향으로 클러스터를 형성
ㄴ 클러스터의 중심점 역할을 하는 평균. 그룹을 형성하는 데이터의 평균.
- 각 데이터(또는 객체)의 특징 값이 유클리디안 공간에 표현 가능해야 함(=수치로 표현해야)
- 형성할 클러스터의 개수(k)가 사전에 주어져야 함
- 간단하지만 실전에서 많이 사용됨
3.2.1 k-means 클러스터링 과정
(1) 유클리디안 공간에 특징값 표현

(2) k(클러스터의 개수)값을 설정, k 클러스터의 초기 중심점(Centroid)를 임의로 설정

(3) 각 객체를 거리가 가까운 중심점에 배정 (중심점 이동)
(4) 같은 중심점에 배정된 객체들의 평균을 계산

(5) 구한 평균 값을 중심점으로 재설정
(6) 각 중심점에 배정된 객체가 변화가 없을 때까지, 3~5단계 반복


3.2.2 k-means 클러스터링의 단점

- 초기 중심점 설정이 최종에 큰 영향을 미침
- 평균값 계산시 이상치(Outlier) 데이터가 미치는 영향이 큼 (배정되면 안 될 이상치가 배정 받음)
- 원 형태로 분류되지 않는 데이터들은 클러스터링 불가 (다른 방법 사용. ex.디비스캔)
4. 강화 학습(Reinforcement Learning)
– 시행 착오를 거치며 보상(피드백)을 통해 서서히 올바른 행동 패턴을 학습해나가는 과정
ex. 문제를 풀면 최종 득점만 알려주고 어떻게 풀지 스스로 생각
ex. 미로에 대해 목표 도달 여부 확인, 보상 주기는 가능하지만 더 나은 방법에 대해서 알려주지 않음
'머신러닝' 카테고리의 다른 글
| [python] 데이터시각화 (0) | 2019.05.13 |
|---|---|
| [aws] lamdba (0) | 2019.04.17 |
| [python] 시작하기 (0) | 2019.04.16 |
| 인공지능의 한계 (0) | 2019.04.16 |
| [python] Selenium을 이용한 Web-Scraping (0) | 2019.04.15 |


