
Stack Building
강화학습 본문
"실수를 통해 올바른 행동을 학습하는 방법"
1. 강화 학습
1-1. 개념

(1) 조작적 조건화(Operant Conditioning): 자발적인 시행 착오로부터 얻은 보상(Reward)에 따라 행동을 형성하는 것
(2) 강화 학습(Reinforcement Learning)
- 강화: 조작적 조건화가 일어날 때, 어떤 행동의 빈도가 증가하는 것
- 강화 학습: 시행 착오(조작적 조건화)를 거치며 보상을 통해 서서히 올바른 행동 패턴을 학습해나가는 과정
=> 목적: 누적 보상이 최대가 되도록 하는 정책을 찾는 것
(3) 정책(Policy): 객체가 어떤 상태에 놓였을 때 어떤 행동을 어느 정도 확률로 선택할지에 대한 지침
(4) 보상의 할인: 보상을 받는 선택을 할 때에는 반드시 일정한 패널티가 따르기 마련이다. 현재로부터 먼 미래일수록 보상을 할인하여 환산하는 것을 보상의 할인이라고 한다. 보통 할인율은 시간이 흐를수록 거듭제곱하여 적용한다. 예를 들어 t 시점에서 할인율^0이라면, t+1시점에서는 할인율^1으로 본다.
(5) 할인 누적 보상(Discounted Return)

각 시점 별로 할인율이 적용된 보상을 누적한 것으로, 객체 행동 패턴의 좋고 나쁨을 판단하기 위한 지표로 활용한다. 위 그림은 할인 누적 보상을 계산하여 가치를 평가한 것이다. 그래프는 네트워크 마케팅의 사례를 표현한 것인데, 얼핏 보기에는 50을 투자하고 나서 100의 수익을 얻으니 이익처럼 보이지만, 이것은 결국 미래의 보상이므로 보상을 할인하여 생각해야 한다. 할인율은 경험이 많은 사람이 세팅하게 된다.
1-2. 정책과 할인 누적 보상

위 그래프와 같이 로봇이 움직인다고 가정하자. 로봇의 상태는 곧 로봇의 위치로, {A, B, C, D, E}가 될 수 있다. 로봇의 행동은 {이동하기}로 볼 수 있다. 로봇의 행동 지침이 되는 정책은 두 가지가 있다. 정책 1은 가능한 한 한 오른쪽으로 이동한다는 것이다. 오른쪽으로 갈수 있으면 오른쪽, 아니면 위로 이동한다. 양쪽 다 불가능한 경우에는 그 자리에 머문다. 정책 2는 가능한 한 위로 이동한다는 것이다. 위로 갈수 있으면 위로, 아니면 오른쪽으로 이동한다. 양쪽 다 불가능한 경우에는 그 자리에 머문다. 할인율(r)을 0.5와 1.0으로 적용하여 정책에 따라 로봇의 특정 상태(위치)에서 할인 누적 보상을 계산하면 아래와 같다.

이를 통해 다음을 알 수 있다. 1. 할인율이 다르면 어떤 정책이 더 나은지도 달라진다. 2. 각 상태에 대한 할인 누적 보상은 정책에 따라 달라진다. 3. 할인 누적 보상으로 정책을 평가할 경우, 상태에 따라 평가 결과가 달라진다.
2. 강화 학습 과정
"보상을 통해 학습 과정을 평가하며, 최선의 정책을 찾는 방법"
2-1. 강화 학습 과정
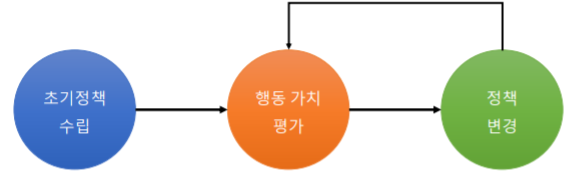
2-2. 행동 가치 평가
(1) 상태 가치 평가 함수
- 특정 상태 s에서 얻을 수 있는 할인 누적 보상을 측정하는 함수
- 상태 s에서 상태 s’의 전이 확률을 기준으로 함
- 행동 가치의 총합
(2) 행동 가치 평가 함수
- 특정 상태 s에서 행동 a를 취한 후 얻을 수 있는 할인 누적 보상을 측정하는 함수
- 행동에 따라 상태 s에서 상태 s’의 전이 확률을 기준으로 함
(3) 가치 평가

2-3. 가치 평가 과정
(1) 온라인 학습: 객체가 움직이는 동안에 조금씩 학습을 진행해 나가는 것.
(2) 배치 학습: 데이터를 한꺼번에 모은 뒤 학습하는 방식
(3) Q학습

최적의 행동 가치 값(Q-값)을 추정하여 강화 학습을 수행하는 학습 방식. 스키너 상자의 새처럼 최적의 행동이 결정될 때까지 이 행동, 저 행동을 반복하는 것이다.
2-4. 정책 수립 방식
(1) 탐욕적 방법: 현시점에서 가장 높은 Q값 갖는 행동을 예상하여 선택하는 것
=> 최적의 행동 가치 값 계산이 불가능하므로 강화 학습이 안 됨
(2) 무작위 방법(Random Method): 현시점에서 발생할 수 있는 행동들을 같은 확률로 선택
=> 최적의 행동 가치 값이 계산되어도 객체가 다른 행동을 할 가능성이 매우 높음
(3) 볼츠만 탐색 정책: (1)+(2). 1번째 학습 시도 단계에서 행동을 선택할 때 현 시점에서 얻을 수 있는 보상을 확률 분포로 적용하여 행동을 선택(샘플링)한 후, 계산된 Q값(누적 보상)에 따라 현재 Q값이 이전 Q값보다 높도록 행동을 선택하는 확률 분포를 조정한다.
3. 황금 모으기 게임

로봇이 위 그림과 같은 구조의 미로를 돌아다니며 황금을 모으는 게임을 수행한다. 단, 로봇은 내부 구조를 모르기 때문에 효율적으로 금을 수집하는 방법을 모른다. 로봇에게 있어 황금을 모을 수 있는 행동 패턴이 곧 정책이 된다. 로봇에게 최선의 정책은 황금을 최대한 많이 모을 수 있는 행동 패턴을 만들어 가는 것이다. 어떤 분기점이 있는지, 어떤 미래가 있는지 알 수 없고, 모든 시점에서 모든 행동에 따라 할인 보상을 계산하려면 모든 미래를 가정해야 하므로 계산이 불가능한 경우이므로 온라인 학습이 필요하다. 로봇이 탐욕적 방법으로 움직이면 첫번째에서 가장 왼쪽으로 갈 것이다. 그러나 볼츠만 탐색 정책을 적용하면 초기에는 0.83, 0.03, 0.14 정도의 확률을 각 브랜치에 적용시킨다. 이후 랜덤하게 선택하여 반복적으로 학습하며 확률을 조정해 나간다. 탐욕적 방법으로 갔을 경우에는 괜찮은 결과는 나오지만 최선이 아닌 반면, 볼츠만 탐색으로는 확률적으로 최선의 결과를 낼 수 있게 되는 것이다.
4. 알파고의 구성 원리
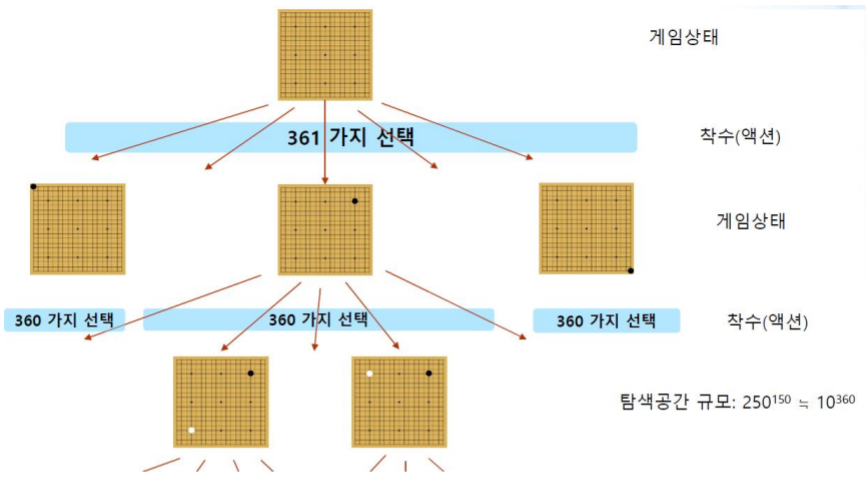
4-1. 인공지능에서 바둑의 수 결정
(1) 초기
(2) 조정
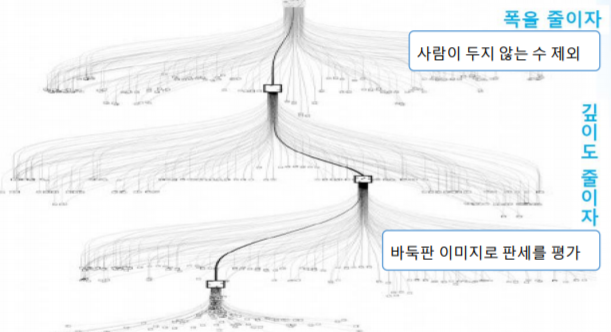
- 상대방이 두지 않은 수에 대한 경우의 수 계산 중지 (폭 줄이기)
- 모든 수를 예측하지 않고 2-3수 앞을 예측 (깊이 줄이기)
4-2. 알파고 파헤치기

전쳬: 바둑 경기 상황 유/불리 분석
(1) 알파고의 차례: 현재 상황 인식하기 (승리, 즉 보상에 얼마나 가까이 있는지)
딥러닝(컨볼루션 신경망): 기보 이미지들로 만든 신경망으로 내 상태가 기보들 중 어느 상태에 가까운지 인식함
기보 이미지: 바둑기사들이 바둑을 한 과정을 기록한 이미지
(2) 현재 상황 기반 어디에 수를 둘지, 그 수에 대한 상대의 다음 수 예측과 상대의 다음 수에 대한 다음 수 예측
강화 학습: 알파고의 정책 고르기
딥러닝(심층신경망): 상대의 수 예측 (예를 들어 뉴런1은 i번째 위치에 흑돌일 것, 뉴런 2는 i번째 위치에 백돌일 것...)
몬테카를로: 나의 수 예측 및 결정
딥러닝(컨볼루션 신경망): 승패 예측
(3) 위 과정 기반, 다수의 미래 예측 이후 가장 많이 둔 최적의 수 선택
알파고 자신과 상대를 대략 4-5번 정도 생각해보고 유불리를 따진다.
강화 학습(몬테카를로): 대응 전략을 학습함 (알파고끼리 붙여서 이긴 행동 지침에 높은 확률을 부여하는 식으로 몇만번 이상 학습)
알파고의 학습능력 (기반: 빅데이터)
(1) 심층신경망: 기보로부터 고수들이 놓는 수 학습
(2) 컨볼루션 신경망: 판세를 보고 승리 가능성을 판단
(3) 강화학습: 컴퓨터끼리 둔 결과로부터 좋은 수 학습
'머신러닝' 카테고리의 다른 글
| [스크랩] 확률과 가능도(우도) (0) | 2019.08.04 |
|---|---|
| 클러스터링 (k-means 알고리즘) (0) | 2019.06.11 |
| 다중선형회귀 원리 (1) | 2019.06.04 |
| 텍스트마이닝 (0) | 2019.06.01 |
| [분류] SVM (0) | 2019.06.01 |



