
Stack Building
텍스트마이닝 본문
1. 개요
1-1. 문서 분류 Document Classification
(1) 특정 연설문을 주고 어떤 후보의 것인지 분류하는 것. 두 명 중 하나의 것으로 분류한다면 binary.
(2) 특정 기사를 주고 어느 종류의 뉴스인지 분류하는 것. 분류할 수 있는 결과가 많다면 binary 여러개의 조합으로 할 수 있다.
1-2. 자동 분류 Automatic Classification

여기서는 이미지나 영상 분류는 일반적으로 딥러닝에서 쓰이기 때문에 텍스트에 치중한다. 문서 자동 분류는 전통적인 머신러닝 문제이다. 훈련과 예측 두 개의 단계로 나눌 수 있다. 1단계, 학습에서는 훈련training이 목적으로, 학습learning을 수행한다. 2단계, 예측에서는 예측prediction이 목적으로, 분류classification를 수행한다. 이 때, 피처는 동일하게 뽑아줘야 한다. 좀 더 큰 시선에서 자동 분류 시스템 구축 과정을 살펴보면, 모델을 학습시키고 분류하는 것 이전에 데이터 수집과 데이터 전처리를 해야 한다.

1-3. Document Data Model
Vector Space Model
- 벡터 스페이스 모델은 포함하고 있는 단어로 문서를 표현한다.
- 각 문서는 term frequency table로 보여진다.
- 각 문서는 단어에 기반한 벡터 하나로 표현된다.
- 텍스트 문서를 단어 색인 등의 프로세싱 토큰으로 구성된 벡터로 표현하는 모델이다.
예시

문서가 벡터이고, term 하나하나가 벡터의 '차원'이다. 데이터베이스에 단 3건의 문서가 있고, 문서 안에 단어도 3개만 존재한다고 가정하자. 문서 1은 {설현:3, 지수:2, 나연:1}, 문서 2는 {설현:1, 나연:2}, 문서 3은 {지수:2, 나연:1, 설현:2}이다. 이를 각 축이 나연, 설현, 지수로 이루어진 공간에 매핑하면 위와 같다.
1-4. Term Frequency Table
(1) 개념적인 텀 프리퀀시 테이블의 생성 과정
문서의 표준화 ▶ Zoning: 논리적인 부분집합 과정. zone으로 파싱한다. ▶ 처리 가능한 최소 단위인 프로세싱 토큰으로 구분한다. ▶ 불용어를 제거한다. ▶ 토큰을 특성에 따라 분류한다. ▶ Stemming(=pruning)어간을 추출한다. ▶ 용어term를 구분한다.
(2) 불용어stopword
분류에 도움이 되지 않는 불필요한 단어들이다. 알고리즘을 사용하여 없애기도 하고 dictionary를 미리 구축하여 그를 lookup하기도 한다. 예를 들어 모든 document에 다 나오는 단어 같은 것은 개체의 특수성을 줄이기 때문에 빼 주는 것이 좋다.
(3) 예시 ★

간단하게 살펴보면, 만약 문서1에 {지수와 나연}이라고 써 있고, 문서2에 {노트북들}이라고 써 있다면, 전체 term의 집합은 {지수, 와, 나연, 노트북, 들}이 될 것이다. 여기에서 불용어를 제거하면 {지수, 나연, 노트북}이 나올 것이고, 이렇게 되면 문서1을 벡터화면 (1, 1, 0), 문서2는 (0, 0, 1)로 표현할 수 있다.
(4) Bag of Words
"문서 내에서 빈도만 센다 ---> 전체 단어들 모아놓고 이 문서는 이 단어 몇 개인지 센다"

벡터 스페이스 모델로 문서를 표현한다. term의 출현 빈도수로 표시한다. 생성 과정은 다음과 같다.
- 토큰화tokenization: 문서를 공백이나 구두점을 기준으로 term(token)들로 분리한다
- 어휘사전 구축: 모든 문서에 나타나는 term들을 수집하여 사전구축한다.
- 인코딩: 어휘사전의 각 term이 문서별로 몇 번 출현하는지 계산하여 벡터로 표현한다. 0의 개수가 많아 희소 행렬 형태가 된다.
(5) TF-IDF (★)
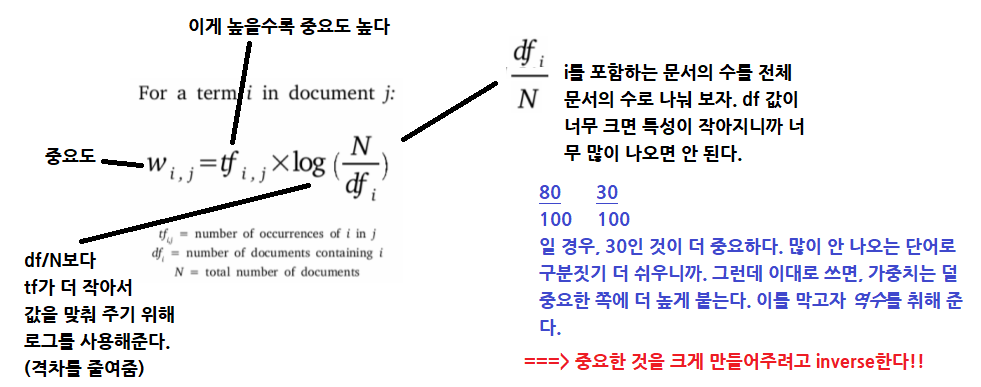
단어를 갯수 그대로 카운트하지 않고 모든 문서에 공통적으로 들어 있는 단어의 경우 문서 구별 능력이 떨어진다고 보고, 가중치를 축소하는 방법이다. tf 방식을 쓸지 tfidf를 쓸지는 특성에 따라 다르다.
(6) Zipf's law
빈도 * 중요도 = 상수
frequency * rank = constant
지프의 법칙에 따르면 어떤 자연어 말뭉치 표현에 나타나는 단어들을 그 사용 빈도가 높은 순서대로 나열했을 때, 모든 단어의 사용 빈도는 해당 단어의 순위에 반비례한다. 따라서 가장 사용 빈도가 높은 단어는 두 번째 단어의 빈도보다 약 두 배 높다. 한마디로 빈도가 높아지면 순위는 낮다.
(7) 정보검색 시스템 Information Retrieval System

검색엔진에서 어떤 문서의 중요도는 질의어와 관련 있는 문서의 상대적 부합relevance ranking 정도이다. 질의어와 얼마나 유사한가는 코사인 방식, 유클리드 방식 등을 사용한다. term frequency*inverse document frequency로 계산한다. 이 과정은 (6)으로 설명할 수 있다. 위 식의 전개 과정에서 1을 더하는 이유는 0을 방지하기 위해서이다.
1-5. Scikit-learn: 수행 과정을 중심으로
(1) 텍스트 데이터 적재loading

load_files는 폴더 이름을 카테고리로 만들어 로딩하여 텍스트를 특성별로 폴더에 분류해두면 잘 읽어온다. 텍스트와 레이블label을 자동으로 붙인 특별한 bunch 타입 객체를 반환한다. 레이블은 폴더 이름의 알파벳 순서에 따라 0부터 숫자를 부여한다. 서브디렉토리에서만 데이터를 읽어오기 때문에 그 아래에 있는 파일은 무시한다. bunch 타입 객체에는 리스트 타입의 데이터와 타겟 속성이 부여되는데, 데이터에는 텍스트 파일 하나당 원소 하나, 타겟은 카테고리 이름을 레이블로 표현한 것이 부여된다. 파일이 윈도에서 보여지는 순서대로 리스트에 들어가지는 않는다. 예를 들어 data:[file1, file2, ...], target:[0,1,0,...]과 같은 식이다.
이번 예제는 양 극단으로만 분류하는 극성polarity 분석을 사용한다. 감성 분석이기 때문에 세세하게 어느 정도인지 파악하기 힘들어서 양 극단으로만 만드는 것이다.
(2) 텍스트 데이터에서 개행 문자를 삭제한다.

바이너리 인코딩인 바이트 타입인 경우 문자열 앞에 b를 넣어 주어야 한다.
(3) 클래스별 샘플의 개수를 확인한다.

(4) BOW로 표현하기
- CountVectorizer: 문서 집합으로부터 단어의 수를 세어 카운트 행렬 생성. term frequency만 세어준다.
- TfidfVectorizer: 문서 집합으로부터 단어의 수를 세고, TF-IDF 방식으로 단어 가중치를 조정한 카운트 행렬을 생성.

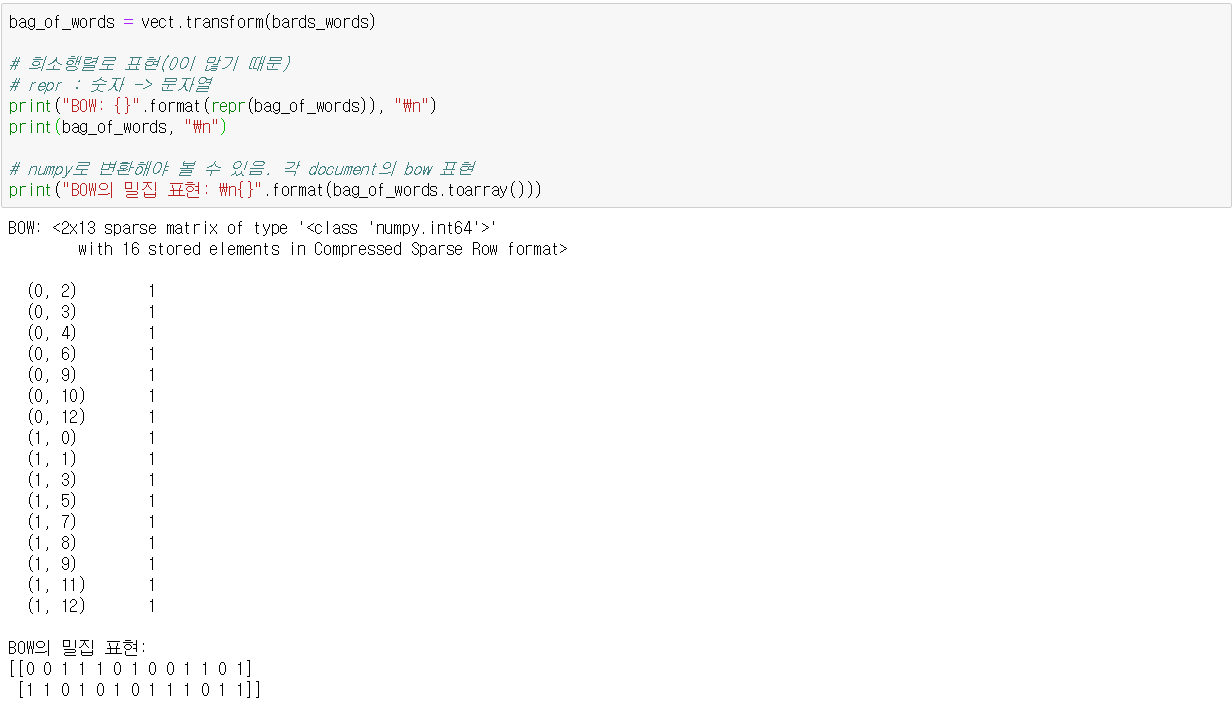
입력 데이터에 대한 BOW는 transform 메소드를 이용한다. 인코딩 과정이라고 볼 수 있겠다. 이제 이 방식을 그대로 하고 있던 분류 과정에 적용해보면 아래와 같다.

(5) 불용어 제거
의미 없는 단어(the, of, all 등)가 있으면 분류의 정확성을 낮추므로, 제거한다. scikit-learn에는 불용어 목록을 미리 가지고 있다. 또 다른 방법으로는 알고리즘 사용, 문서 DB에서 너무 자주 나오는 것은 제외하는 방법이 있다. 아래 코드에서 df는 document frequency의 준말이다. 이 수를 조정하면 전체 디비 기준으로 문서 수 기준을 만들 수 있다. tf는 문서 하나 기준으로 단어 수를 센다.

(6) TF-IDF

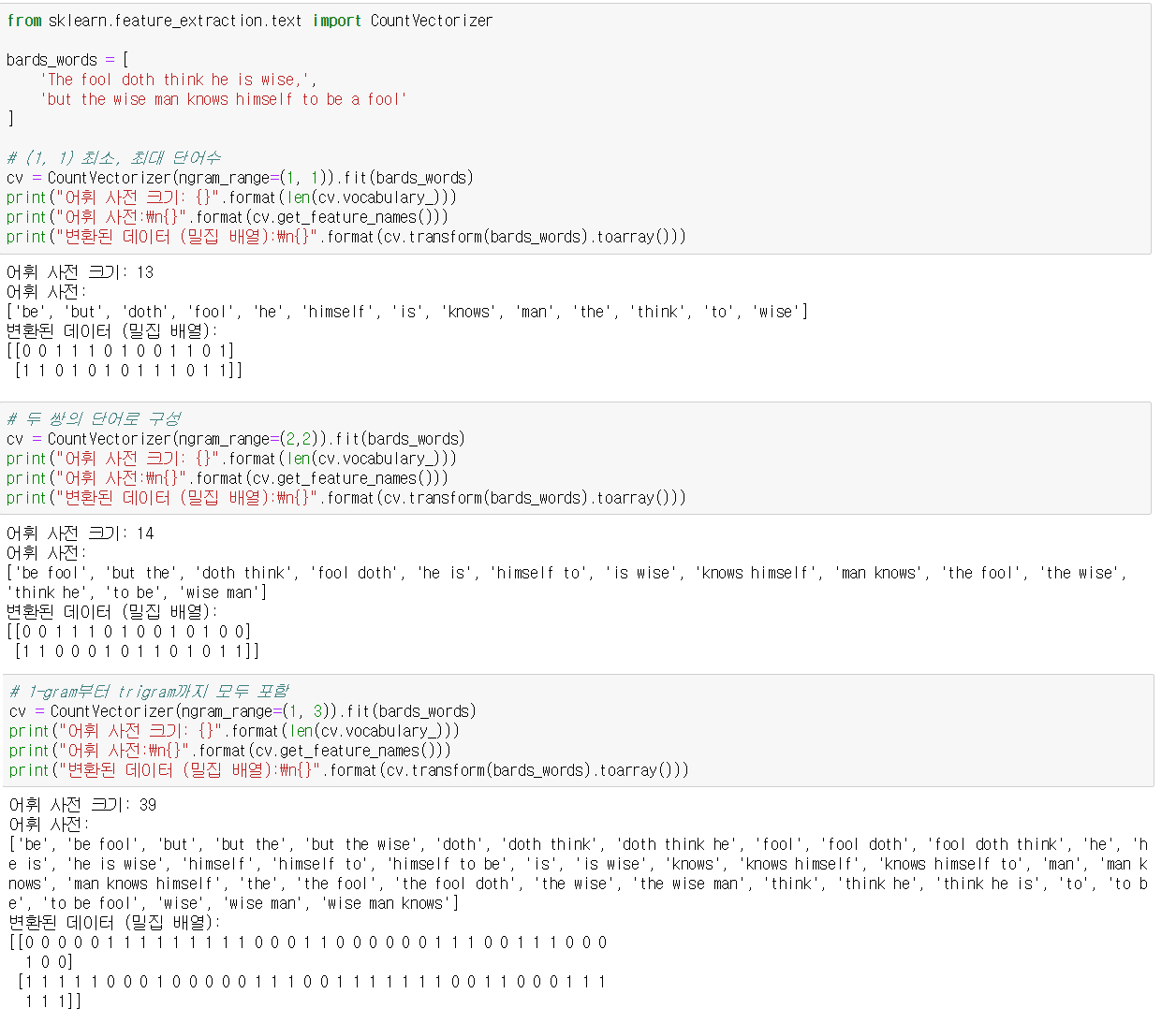
(7) 단어의 쌍으로 구성하는 n-gram 방식
이 방식은 한글에 좋다. 단어 쌍으로 표현하면 단어의 순서나 결합하는 단어의 의미를 표현할 수 있다. 2개 조합은 bigram, 3개 조합은 trigram으로 부른다.
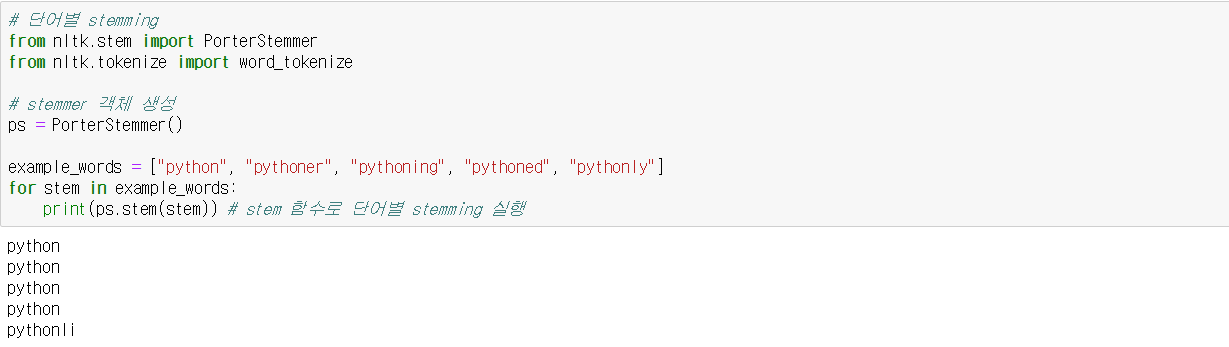
(8) 어간 추출 stemming
어간(stem)이란 활용어가 활용할 때 변하지 않는 부분을 말한다. 보다, 보니, 보고의 stem은 '보'이다. 따라서 어간 추출은 어미를 제외하고 어간만을 추출하는 과정이라고 볼 수 있다. 고급 토큰화의 또 다른 방법에는 표제어 추출이 있는데, 사전을 활용하여 표준말을 추출하는 방법이다. 예를 들어, '보'가 아니라 '보다'를 추출하는 식이다. nltk() 패키지를 사용하면 어간 추출을 할 수 있다.

(9) stemming 기능을 추가한 BOW를 생성

(10) 영문자만 추출하는 방법 (숫자, 구두점 제거)
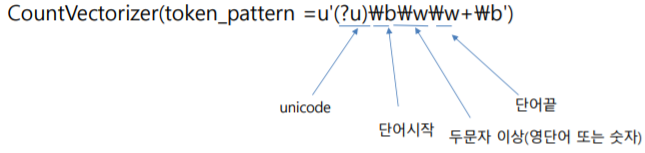
2. 영문 텍스트 분석
2-1. 나이브 베이즈 (numpy)

어떤 클래스에 속하는지 알려면 P(unseen|Class=3)과 P(unseen|Class=4)를 비교하면 된다. 피처가 두 개이기 때문에 각각의 피처가 각각의 클래스일 확률을 곱하면 알 수 있다.
2-2. 텍스트 분류를 위한 나이브 베이즈
(1) 트레이닝 데이터

(2) unseen data (예측하고자 하는 document X)

(3) 방법
- 구하고자 하는 것은 P(a = 1 , b = 0 , c = 1, g = 0 | Neg)과 P(a = 1 , b = 0 , c = 1, g = 0 | Pos)
- 그 둘을 구하려면 결국 P( a = 1 | Neg) * P(b = 0 | Neg) * P(c = 1 | Neg) * P(g = 0 | Neg)과 P(a = 1 | Pos) * P (b = 0 | Pos) * P(c = 1 | Pos) * P(g = 0 | Pos) 을 구해야 한다.
- 각각을 텍스트 분류에 적합한 Multinomial 분포를 사용해 추정한 후, P(Neg)=7/12, P(Pos)=5/12를 곱해 클래스를 예측한다.
(4) 나이브 베이즈 종류
- 베르누이: 두 개의 값만 가질 수 있음
- 멀티노미알: 이산 데이터. 등급, 클래스, 라벨 등. 텍스트 학습에 적합.
- 가우시안: 연속 데이터. 정규 분포 가정.
2-3. Scikit-learn
(1) numpy로 나이브 베이지안 하기

(2) 영화평 자동 분류하기
"fit ---> transform ---> predict"

(3) 알파 값을 튜닝하여 멀티노미알 분포 스무딩

(4) TF-IDF 사용 자동 분류 (TFidVectorizer 사용)

3. 한글 텍스트 처리 기법
3-1. koNLPy
한국어 정보처리를 위한 파이썬 패키지로, 다양한 종류의 한글 형태소 분석기를 지원한다.
3-2. Okt(Open Korean Text)
스칼라로 작성된 한글 토크나이저 오픈 소스. 이전 이름은 Twitter였다.

morphs는 절을 형태소로 파싱해준다. 이 함수의 파라미터로 norm을 주면 토큰을 정규화하고, stem을 주면 스테밍을 해주는 것이다. 그냥 구문만 넣어줘도 괜찮다. nouns 함수는 명사 추출기이고, phrase 추출기는 절 추출기이다. pos는 Part Of Speech의 약자로, 태깅까지 해준다. 이 함수의 파라미터로 추가로 join이 있는데, 참일 경우 형태소와 태그의 joined set을 반환한다.
(1) Okt 형태소 분석기로 토크나이저 함수 생성 및 개선

(2) 나이브 베이지안 분류기 생성 및 사용

multinomial 나이브 베이즈를 사용한다. 실행 시간이 오래 걸린다. 텍스트의 경우 특징 수가 많아서 차원 축소/ 특징 선택 등의 특징 수를 줄이려는 노력이 필요하다.

3-3. 한글 영화평 데이터 분류
(1) 데이터 확인
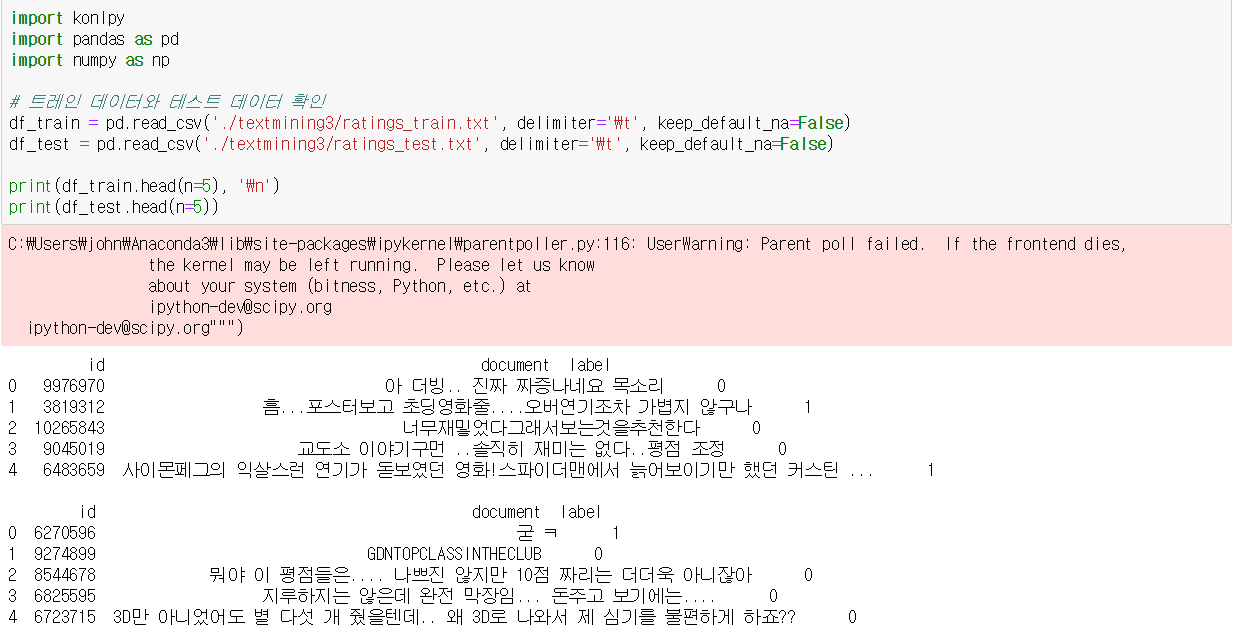
(2) 영화평 문자열과 평점 레이블 확인

4. 워드 클라우드
4-1. 기본
(1) 영어
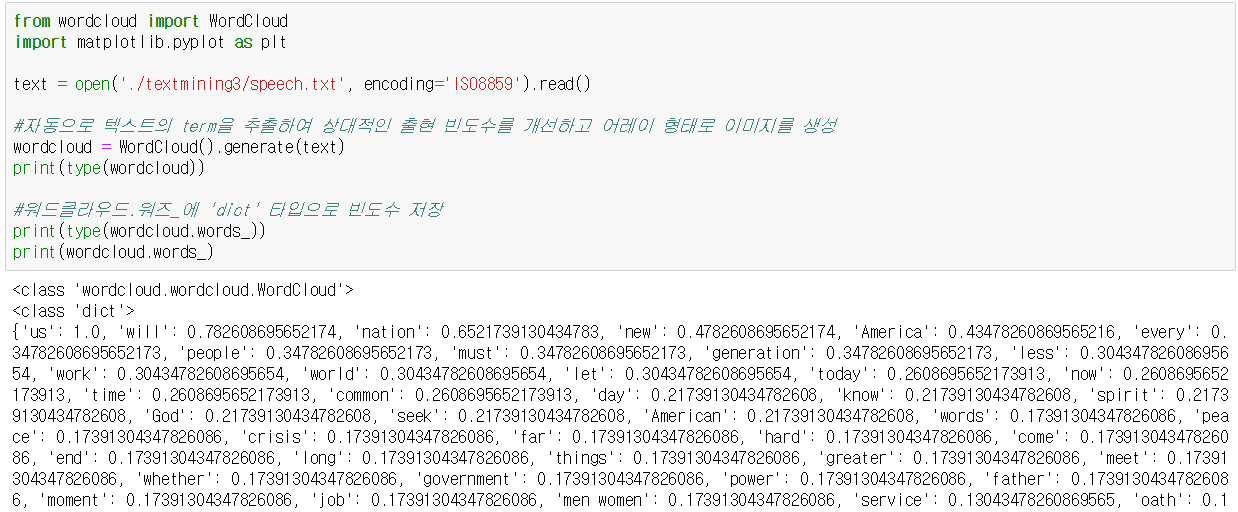

(2) 한글


4-2. 그림
(1) 앨리스

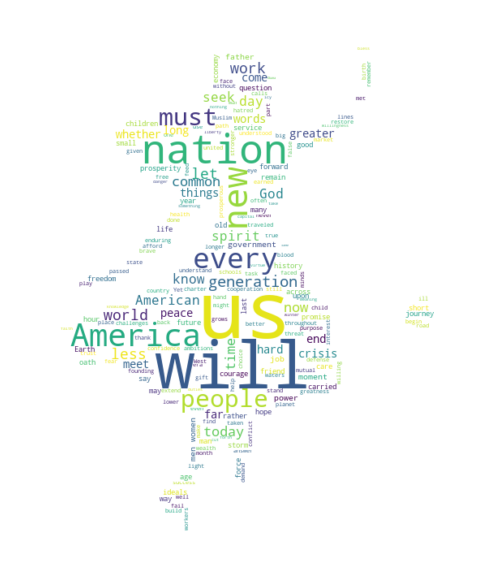
(2) 지도


'머신러닝' 카테고리의 다른 글
| 강화학습 (1) | 2019.06.04 |
|---|---|
| 다중선형회귀 원리 (1) | 2019.06.04 |
| [분류] SVM (0) | 2019.06.01 |
| [분류] 로지스틱 회귀 (0) | 2019.05.26 |
| k-fold 교차 검증 (0) | 2019.05.26 |



